Serve multiple generative AI models¶
A company wants to deploy multiple large language models (LLMs) to a cluster to serve different workloads.
For example, they might want to deploy a Gemma3 model for a chatbot interface and a DeepSeek model for a recommendation application.
The company needs to ensure optimal serving performance for these LLMs.
By using an Inference Gateway, you can deploy these LLMs on your cluster with your chosen accelerator configuration in an InferencePool.
You can then route requests based on the model name (such as chatbot and recommender) and the Criticality property.
How¶
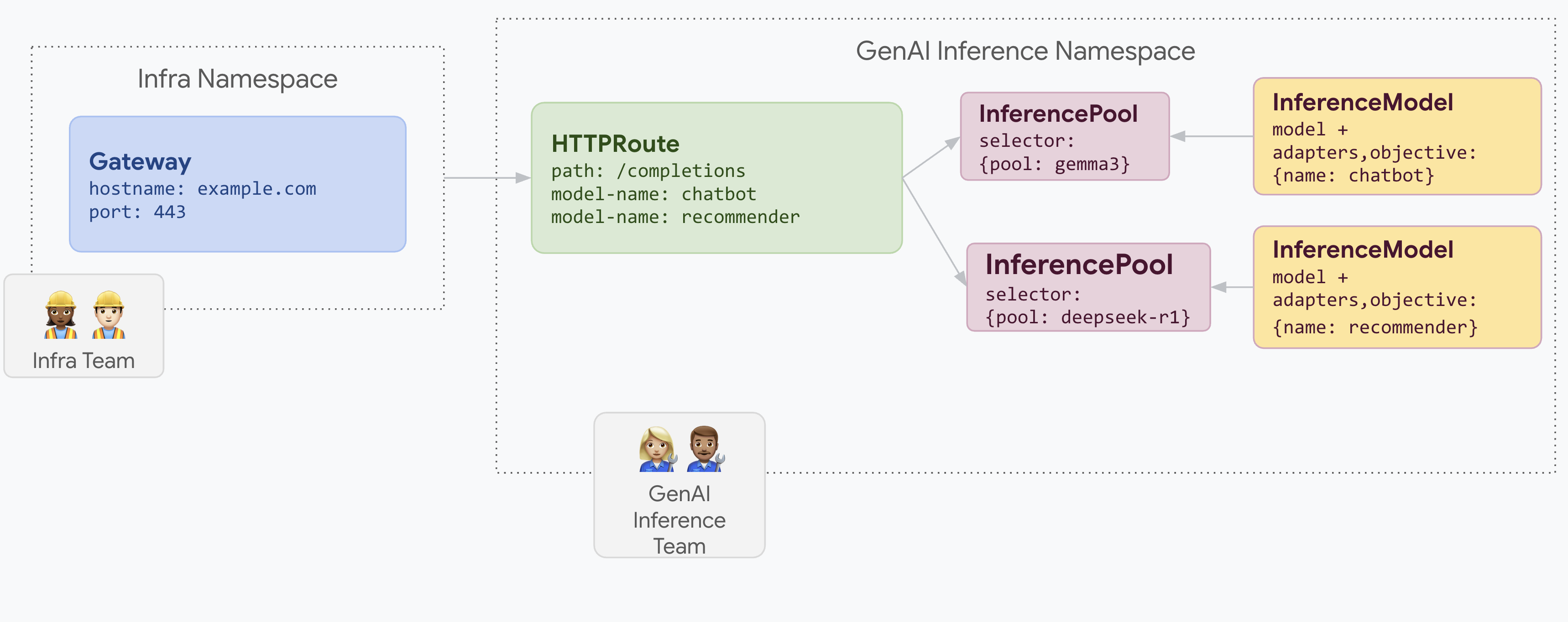
The following diagram illustrates how an Inference Gateway routes requests to different models based on the model name.
The model name is extracted by Body-Based routing (BBR)
from the request body to the header. The header is then matched to dispatch
requests to different InferencePool (and their EPPs) instances.
Deploy Body-Based Routing¶
To enable body-based routing, you need to deploy the Body-Based Routing ExtProc server using Helm. Depending on your Gateway provider, you can use one of the following commands:
helm install body-based-router \
--set provider.name=gke \
--version v0.5.1 \
oci://registry.k8s.io/gateway-api-inference-extension/charts/body-based-routing
helm install body-based-router \
--set provider.name=istio \
--version v0.5.1 \
oci://registry.k8s.io/gateway-api-inference-extension/charts/body-based-routing
helm install body-based-router \
--version v0.5.1 \
oci://registry.k8s.io/gateway-api-inference-extension/charts/body-based-routing
Configure HTTPRoute¶
This example illustrates a conceptual example regarding how to use the HTTPRoute object to route based on model name like “chatbot” or “recommender” to InferencePool.
apiVersion: gateway.networking.k8s.io/v1
kind: HTTPRoute
metadata:
name: routes-to-llms
spec:
parentRefs:
- name: inference-gateway
rules:
- matches:
- headers:
- type: Exact
name: X-Gateway-Model-Name # (1)!
value: chatbot
path:
type: PathPrefix
value: /
backendRefs:
- name: gemma3
group: inference.networking.x-k8s.io
kind: InferencePool
- matches:
- headers:
- type: Exact
name: X-Gateway-Model-Name # (2)!
value: recommender
path:
type: PathPrefix
value: /
backendRefs:
- name: deepseek-r1
group: inference.networking.x-k8s.io
kind: InferencePool
- BBR is being used to copy the model name from the request body to the header with key
X-Gateway-Model-Name. The header can then be used in theHTTPRouteto route requests to differentInferencePoolinstances. - BBR is being used to copy the model name from the request body to the header with key
X-Gateway-Model-Name. The header can then be used in theHTTPRouteto route requests to differentInferencePoolinstances.
Try it out¶
- Get the gateway IP:
IP=$(kubectl get gateway/inference-gateway -o jsonpath='{.status.addresses[0].value}'); PORT=80
-
Send a few requests to model
chatbotas follows:curl -X POST -i ${IP}:${PORT}/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{ "model": "chatbot", "messages": [{"role": "user", "content": "What is the color of the sky?"}], "max_tokens": 100, "temperature": 0 }' -
Send a few requests to model
recommenderas follows:curl -X POST -i ${IP}:${PORT}/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{ "model": "recommender", "messages": [{"role": "user", "content": "Give me restaurant recommendations in Paris"}], "max_tokens": 100, "temperature": 0 }'
-
Send a few requests to model
chatbotas follows:curl -X POST -i ${IP}:${PORT}/v1/completions \ -H 'Content-Type: application/json' \ -d '{ "model": "chatbot", "prompt": "What is the color of the sky", "max_tokens": 100, "temperature": 0 }' -
Send a few requests to model
recommenderas follows:curl -X POST -i ${IP}:${PORT}/v1/completions \ -H 'Content-Type: application/json' \ -d '{ "model": "recommender", "prompt": "Give me restaurant recommendations in Paris", "max_tokens": 100, "temperature": 0 }'